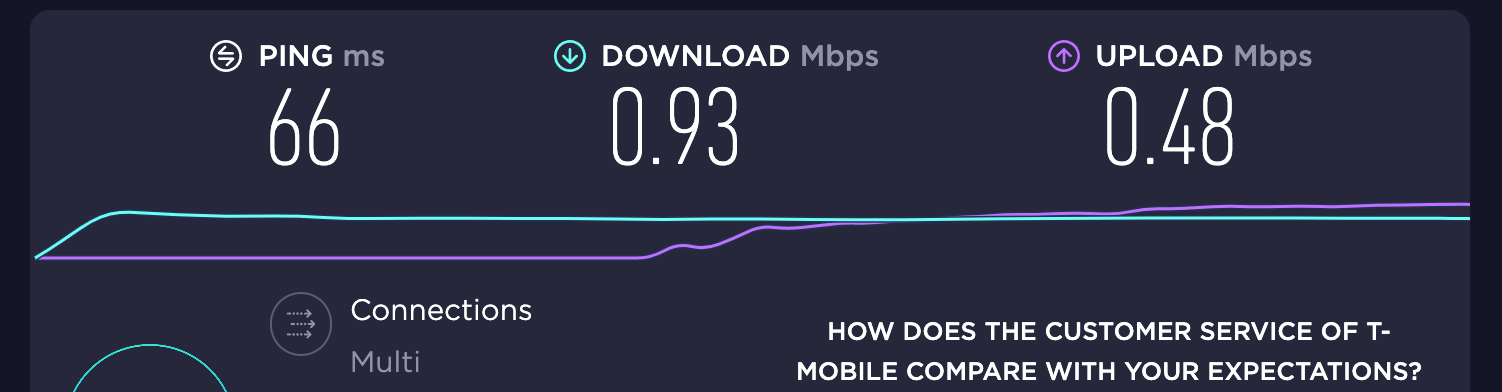
Before we start, we need to understand how carrier actually identifies your traffic from tethering. If you google, a lot of people will say carriers use TTL to detect tethering. While this could be true, it doesn’t seem like modifying TTL helps.
It’s actually pretty simple – the phone told the carrier on its own! How do you know? Just go to whatsmyip.org and check if you IP addresses are the same from the phone and from a device that’s using the hotspot.
You will see that you actually get two different IPs! This means that as you’re tethering, the traffic isn’t sent through the same channel as the traffic on the phone!
As a matter of fact, when you’re tethering, the phone will use a different APN (usually called dun) instead of the regular APN that traffic goes through. It’s super easy for the carrier to then throttle your traffic.
Now we figured out that how carrier detects tethering traffic, let’s figure out how to bypass it.
Option 1: Use a device that doesn’t expose your traffic.
If you have a rooted Android phone, I believe you will be able to modify the iptable to route traffic to the phones “regular” apn. You might be able to find some MIFIs that will do this for you automatically on the market.
However, most of us no longer use rooted phones anymore, and this is basically impossible for iOS either. What do we do?
Option 2: Reroute traffic back to the “regular” link using a proxy.
There is a very interesting app called Every Proxy, which is able to setup a proxy server on the phone. If you point your other device (like a PC/mac) that connects to the hotspot to use the proxy, you will be able to reroute all the tethering traffic back to the phone – which the carrier will no longer be able to identify. For the proxy setup on the PC/mac, just use the system proxy settings for it
第二代的个人计算设备,手机,构筑出了一个新的生态。与此同时软件分发的数字化让苹果和谷歌吃到了大量的平台税,从此赚的盆满钵满。与此同时,苹果对于广告的盈利模式显然是不喜欢的,最根本的原因还是因为可以不用交平台税。于是 Facebook 和 Apple 的梁子算是结下了。本质上还是两种不同商业模式的竞争。
FB是第二代系统的受益者,同时 Apple 的土皇帝地位显然让FB也感到坐立难安。手机这个赛道现在进入也太晚了(更何况FB曾经试图进入过,只不过失败了)。与其在手机上和 Google 以及 Apple 继续纠缠,FB 决定直接跳过手机,进入到FB认定的下一代个人计算平台,也就是VR。
People who know me know that I have a biased view of processes – and that’s probably because I’m working for Facebook at this moment, and generally speaking larger companies have more processes than smaller ones. While I have a lot of ideas while discussing with my coworkers about processes, I’d like to put down some more structured thoughts in this article.
First of all, what I believe that makes a company / organization / team successful boils down to two very fundamental things:
People, Domain.
Key people is a multiplier to an organization. They unlock potentials and make impossibles possible. They are people of integrity who would consider faking or even taking shortcuts unacceptable – and they would quit if forced to do so. They don’t blindly follow instructions, and have their own thought of thinking. They have the domain knowledge, and willing to master new domains whenever needed. They ask rest of the org to be the same of them, or at least a portion of them.
Domain defines how well the people power can be unleashed. Even super talented person cannot fight against trends. A hot domain may make someone less talented to look like they’re super talented. However, it’s worth noting that if you have the right people, talented people can find the right domain (think the shift to mobile and the companies who succeeded and failed)
The rest plays much less critical roles. Even with a bad process, the good ones will still figure out how to navigate it and find the answer, while a good process cannot magically turn something shitty into great.
Steve Jobs had a great comment on process vs content – which I take the content as “the content great people produce”. I can’t agree more with him.
When I think about the greatest CEOs in the tech industry, they all seem to care a lot about details, and they have a lot of thoughts on them. Take Elon Musk as an example, even as busy as an CEO (or CEOs), he still knows how a rocket works in details.
So am I against processes? No. I think they are important, though from a different way.
Processes are there to make the best use of the talented people.
While we want to work with as many talented people as possible, the sad fact is that we only have a few talents. Processes exist because they give them power, or reduce the friction of having the talented people taking care of the rest. Aka, letting the great people to become more efficient in creating content.
Let’s take an example. A team used to have unstructured roadmapping processes. This worked great because we have a great TL who understands product and engineering. This worked until the team started to grow, potentially by 2x or 3x – the TL can no longer cover every roadmapping if nothing changes.
To address this problem, we can create such processes:
Make sure all the product ideas are vetted and ordered upfront.
Make sure all product ideas have well-documented plan so that it’s super clear to the TL what needs to be built.
Have this TL go through the docs and give early feedbacks on each project.
Have a review session to finalize on the roadmap.
In this process, 1 reduces prevents low quality ideas to go through the roadmapping session. 2 reduces the back & forth between product & engineer, and also pushes product to think through the project in more details. 3 turns the back & forth into an async communications and 4 ensures the “eventual consistency” between product & engineer. This process introduces more work for the product team, but increase the value of time this TL puts into it.
While this example this talent is an engineer, it could be anyone – including yourself. It could also be an important highly productive team in the org.
Processes don’t make sense if you don’t have talents on the team, or they’re not a constraint resource. Processes increase the amount of work for people overall – and only when we can shift some work from the talented to the rest of the team processes start to make sense.
Alright, to end this post, here are my two principles on processes:
Processes are useless if you don’t have the talented person.
Built processes for that person so they create more great content.
Players in high frequency need can beat low frequency need players extremely easily.
Yelp will definitely agree to this statement – they’re getting killed by Google.
Food is the highest frequency need, then drink, then other local services (grocery, autos, karaoke, kart racing, kayaking, wedding, etc etc).
You will probably know you can also order drink from the app where you ordered food, rather than an app where you ordered grocery delivery, even though the nature of the business are not much that different.
Doordash will almost certain enter the business of grocery delivery, killing instacart and shipt.
Doordash has to face Yelp, if it wants to keep its high evaluation after COVID. Yelp is currently only 2.67B while Doordash is 65B. Buying Yelp will be a smart move that will almost pay back immediately after COVID.
Ride sharing will be the next one. Isn’t it nice if you can send some riders to restaurants, then immediately pick up some food from the very same restaurant (or in the same plaza), deliver it to the residential area, and then getting another ride request from the residential area to the business area?
The list goes on and on. The path is clear, the rest is just execution. Doordash had amazing execution in the past (and strategy as well for sure!) – otherwise they would not have won the delivery war.